String具有不可变性
1)当对字符串进行重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值
2)当对现有的字符串进行连接操作的时候,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
3)当调用String的 replace() 方法修改指定字符或字符串的时候,也需要重新指定内存区域赋值,不能使用原有的value进行赋值
注意:String声明为final,不可被继承
1
2
3
4
5
6
| @Test
public void test1() {
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2)
}
|
1
2
3
4
5
6
7
| @Test
public void test2() {
String s1 = "abc";
String s2 = "abc";
s1 = "hello"
System.out.println(s1 == s2)
}
|
1
2
3
4
5
6
7
8
| @Test
public void test3() {
String s1 = "abc";
String s2 = "abc";
s2 += "def";
System.out.println(s2);
System.out.println(s1);
}
|
1
2
3
4
5
6
7
| @Test
public void test4() {
String s1 = "abc";
String s2 = s1.replace('a', 'm');
System.out.println(s1);
System.out.println(s2);
}
|
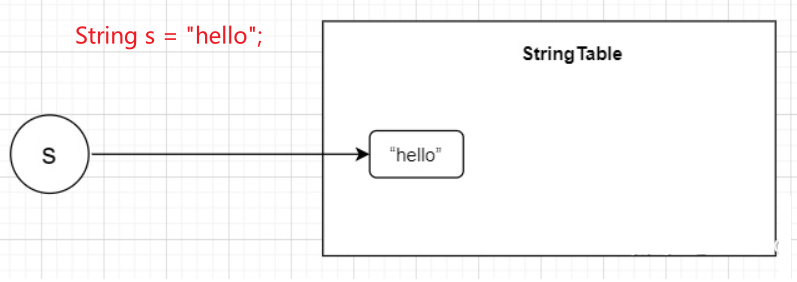
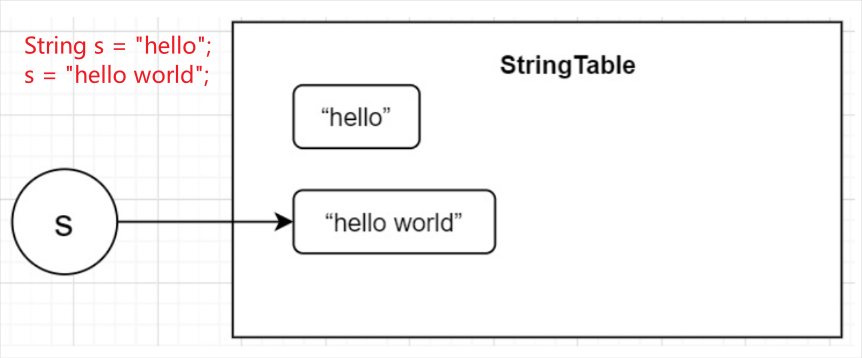
字符串常量池不会存储相同内容的字符串
1、String的String Pool是一个固定大小的 Hashtable,如果放进String Pool的String非常多,就会造成Hash冲突严重,导致链表会很长,而链表长了之后直接会造成的影响是当调用String.intern时性能会下降
2、jdk6中StringTable的长度是固定的(1009),jdk7中StringTable的长度默认是60013,jdk8的可设置的最小值是1009。两个版本都可以**调整StringTable的值,使用 -XX:StringTableSize **
String的内存分配
概述
8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种:
1、直接使用双引号声明出来的String对象会直接存储在常量池中(比如: String info = “abc” )
2、也可以使用String提供的intern()方法手动将字符串加入常量池中
1
2
3
4
5
6
7
8
9
10
| public static void main(String[] args) {
int i = 1;
Object obj = new Object();
Memory mem = new Memory();
mem.foo(obj);
}
private void foo(Object param) {
String str = param.toString();
System.out.println(str);
}
|
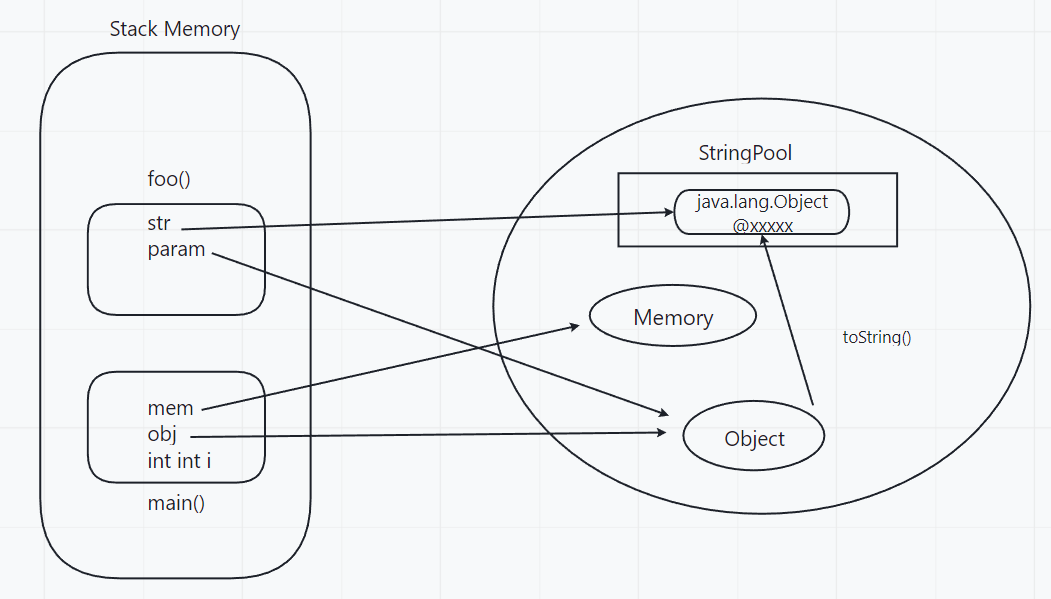
注意:
完全相同的字符串字面量,应该包含同样的Unicode字符序列(包含同一份码点序列的常量)
并且必须是指向同一个String类实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public static void main(String[] args) {
System.out.println();
System.out.println("1");
System.out.println("2");System.out.println("3");
System.out.println("4");System.out.println("5");
System.out.println("6");System.out.println("7");
System.out.println("8");System.out.println("9");
System.out.println("10");
System.out.println("1");
System.out.println("2");
System.out.println("3");System.out.println("4");
System.out.println("5");System.out.println("6");
System.out.println("7");System.out.println("8");
System.out.println("9");
System.out.println("10");
}
|
字符串拼接操作
常量与常量的拼接结果在常量池,原理是编译器优化常量池中不会存在相同内容的常量
拼接中只有其中有一个是变量,拼接后的结果就在堆中。变量拼接的原理是 StringBulider
如果拼接的结果调用 intern方法,则主动将常量池中还没有的字符串对象放到池中,并返回此对象的地址
测试1
常量与常量拼接
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public void test1(){
String s1 = "a" + "b" + "c";
String s2 = "abc";
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
|
测试2
常量与常量,常量与变量,变量与变量拼接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| @Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);
System.out.println(s3 == s5);
System.out.println(s3 == s6);
System.out.println(s3 == s7);
System.out.println(s5 == s6);
System.out.println(s5 == s7);
System.out.println(s6 == s7);
String s8 = s6.intern();
System.out.println(s3 == s8);
}
|
测试3
1
2
3
4
5
6
7
8
| @Test
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
|
如下的s1 + s2 的执行细节:
① StringBuilder s3 = new StringBuilder();
② s3.append("a")
③ s3.append("b")
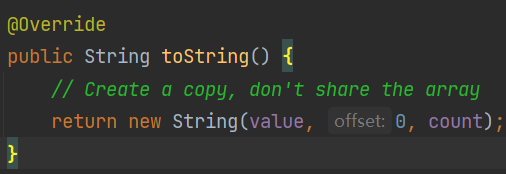
④ s3.toString() –> 约等于 new String("ab")
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer
测试4
1、字符串拼接操作不一定使用的是StringBuilder。如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非StringBuilder的方式。
2、针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上final的时候建议使用上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Test
public void test4(){
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);
}
@Test
public void test5(){
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop";
System.out.println(s1 == s3);
final String s4 = "javaEE";
String s5 = s4 + "hadoop";
System.out.println(s1 == s5);
}
|
测试5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Test
public void test6(){
long start = System.currentTimeMillis();
method1(100000);
method2(100000);
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
}
public void method1(int highLevel){
String src = "";
for(int i = 0;i < highLevel;i++){
src = src + "a";
}
}
public void method2(int highLevel){
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
}
|
执行效率:通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式
1、StringBuilder的append()的方式:自始至终中只创建过一个StringBuilder的对象
2、使用String的字符串拼接方式:创建过多个StringBuilder和String的对象
3、使用String的字符串拼接方式:内存中由于创建了较多的StringBuilder和String的对象,内存占用更大;如果进行GC,需要花费额外的时间。
intern()的用法

1、intern方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放到字符串常量池里面
2、在任意字符串上调用intern方法,其返回结果所指向的类实例必须和直接以常量形式出现的字符串实例完全相同
如:("a"+"b"+"c").intern() == "abc"
3、其实intern方法就是确保字符串在内存中只有一份拷贝。这样可以节约内存空间,加快字符串操作任务的执行速度(该值会存放在字符串常量池)
保证变量指向字符串常量池的方法
字面量定义的方式
调用intern()
1
2
| String s = new String("test").intern();
String s = new StringBuilder("test").toString().intern();
|
问题案例
1、new String("")会创建几个对象
1
| String str = new String("ab");
|
两个对象,一个对象是:new关键字在堆空间创建的。另一个对象是:字符串常量池中的对象”ab”。 字节码指令:ldc
注意:此时在字符串常量池中,存在”ab”
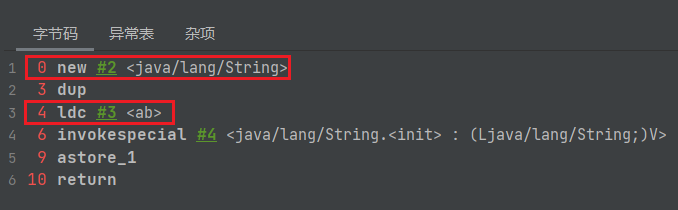
2、new String("a")+new String("b")会创建几个对象
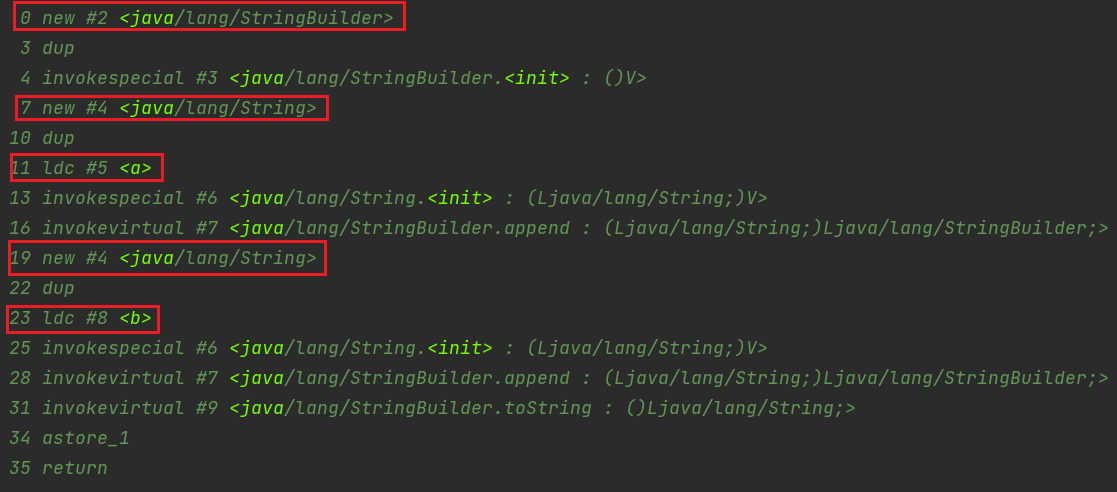
对象1:new StringBuilder()
对象2: new String(“a”)
对象3: 常量池中的”a”
对象4: new String(“b”)
对象5: 常量池中的”b”

对象6 :new String(“ab”)
注意:toString()的调用,在字符串常量池中,没有生成”ab”
测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public static void main(String[] args) {
String s1 = new String("1");
s1.intern();
String s2 = "1";
System.out.println(s1 == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
|
1
2
3
4
5
6
7
8
9
| public static void main(String[] args) {
String s3 = new String("1") + new String("1");
String s4 = "11";
String s5 = s3.intern();
System.out.println(s3 == s4);
System.out.println(s5 == s4);
}
|
总结instern方法
jdk1.6中
将这个字符串对象尝试放入字符串常量池
如果字符串常量池有,则不会放入。返回已有的串池中的对象的地址
如果没有,会把此对象复制一份,放入字符串常量池,返回字符串常量池中的对象地址
jdk1.7中
将这个字符串对象尝试放入字符串常量池
如果字符串常量池有,则不会放入。返回已有的串池中的对象的地址
如果没有,会把此对象的引用地址复制一份,放入字符串常量池,返回字符串常量池中的对象地址
intern()练习
1
2
3
4
5
6
7
8
9
10
11
| public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");
String s2 = s.intern();
System.out.println(s2 == "ab");
System.out.println(s == "ab");
}
|
1
2
3
4
5
6
7
| public static void main(String[] args) {
String s1 = new String("ab");
s1.intern();
String s2 = "ab";
System.out.println(s1 == s2);
}
|






